

Why A/B Tests Lie When Your Traffic Mix Shifts
You’re five days into an A/B test and your results look promising. The variant shows an eight percent lead over the control with healthy sample sizes and nearing significance. However, following the launch of a storewide clearance sale on day six, that lift vanishes by day eight, leaving the control and variant neck-and-neck. While the standard response is to abandon the test because the variant "failed," this may be a misinterpretation.
The issue often isn't the variant's performance, but a fundamental shift in the audience.
By definition, an A/B test evaluates two page versions while assuming all other variables, including traffic composition, remain constant. In reality, the traffic mix is rarely stable. If you analyze test results without accounting for exactly who is visiting your site, you are essentially evaluating the wrong data.
The aggregate number is hiding three tests in a trench coat
Most testing tools report one top-line number: overall conversion rate, variant vs. control. That number is a weighted average across all visitors in the test, paid and organic, new and returning, full-price shoppers and discount hunters. Each of those groups has its own baseline conversion rate and its own response to whatever change you made.
When the mix stays stable across the test window, the aggregate is honest. When the mix shifts, the aggregate lies.
Consider an experiment where a specific variant boosts the conversion rate of returning visitors by twelve percent. Because the modification wasn't intended for them, new visitors show no change. During the initial four days, the traffic mix is seventy percent returning and thirty percent new, resulting in a visible aggregate lift. However, on day five, a new paid campaign shifts the composition to thirty percent returning and seventy percent new. Although the variant still provides a twelve percent lift for returning visitors and remains flat for new ones, the total aggregate lift plummets to zero.
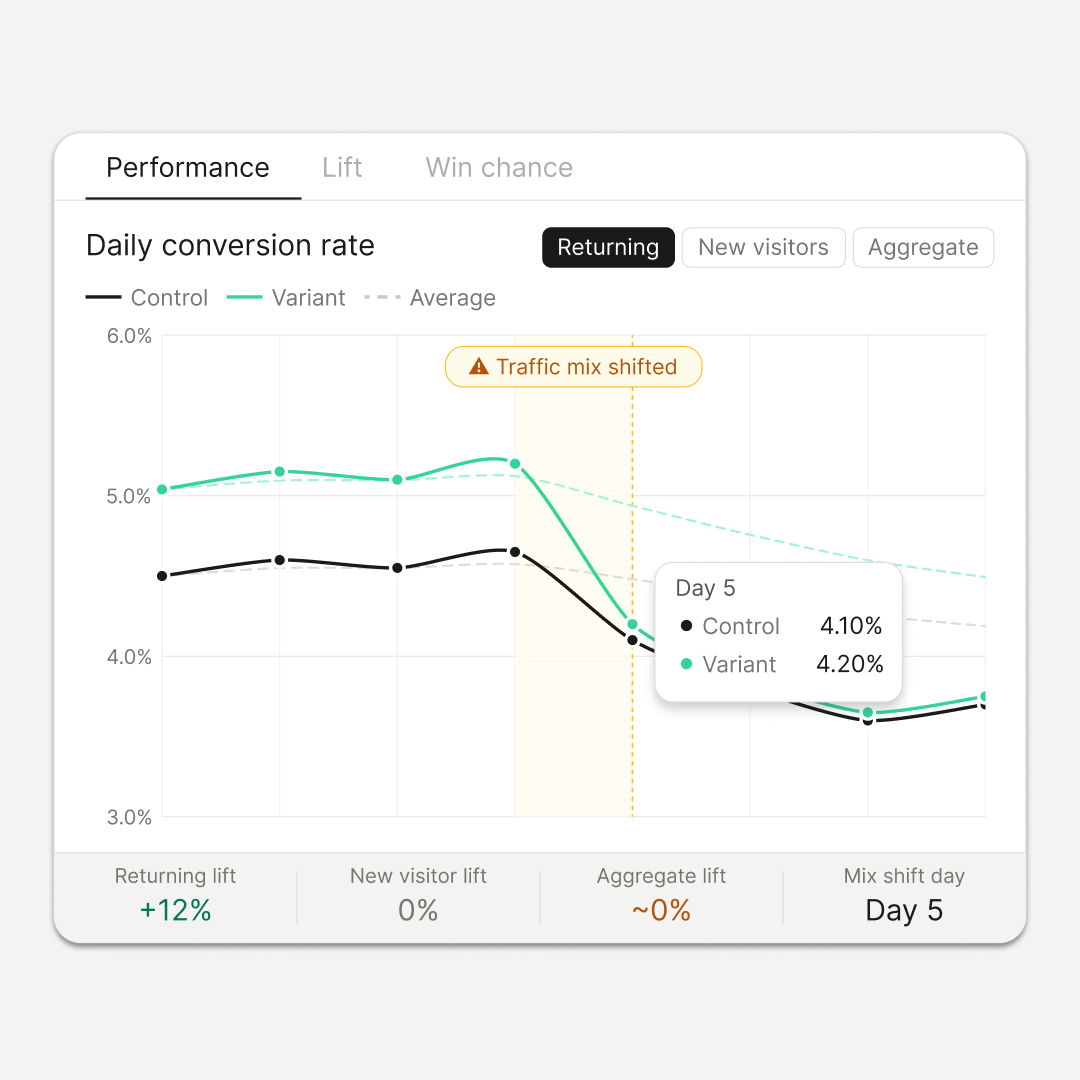
The variant's performance didn't falter; rather, the underlying denominator shifted.
Statisticians call this Simpson's paradox, a trend that holds inside every subgroup but reverses or disappears in the aggregate. In ecommerce testing, it shows up any time traffic composition moves: acquisition pushes, seasonal campaigns, PR spikes, rebrands, sales, affiliate surges. Most testing programs never notice because most testing programs never segment.
The segments that carry signal
Three cuts cover most of what goes wrong.
New vs. returning. Different expectations at the door. Returning visitors know the brand, the product, the price band. New visitors are evaluating all of that in the first few seconds. A trust-building change, be it in form of reviews, UGC, or guarantee language, moves new visitors more than returning. On the other hand, a friction-reduction change, like faster checkout or persistent cart, moves returning more than new. Testing either against the aggregate hides the effect you produced.
Paid vs. organic. Paid traffic usually arrives with narrow, declared intent. They clicked an ad for a product, they land on a page about that product, the decision path is short. Organic traffic is broader; here, users are exploring, comparing, and reading. Urgency cues like scarcity counters and countdown timers tend to lift paid conversions and do very little for organic browsers. If your test population leans one way during the test and the other at rollout, your projected lift evaporates.
Discount-driven vs. full-price. Promo shoppers convert on price, while everyone else converts on fit, trust, and positioning. A test that wins during a sale window can flip negative the rest of the quarter, same page, different audience.
The choice of segmentation should be driven by your hypothesis. It is unnecessary to split paid versus organic traffic for a test addressing first-time buyer concerns, just as an urgency-based experiment does not require a new versus returning visitor breakdown. Over-segmenting every experiment risks diluting your findings with underpowered data; instead, select the specific cut that aligns with the focus of your test.
Reading tests when the mix shifts
When traffic composition begins to fluctuate, these four strategies ensure your test signal remains accurate.
1. Pre-define your primary segment. Document your target audience explicitly, such as "returning mobile visitors," before the test begins. While observing other segments is acceptable, the final decision must rest on the pre-declared group. Retrofitting, the act of picking a successful segment only after seeing the data, is essentially p-hacking disguised as analysis.
2. Track composition alongside conversions. Include visitor types and traffic sources in your daily reviews. If you notice the mix shifting more than 10% to 15% from your baseline, hold off on drawing any conclusions.
3. Distinguish between pausing and restarting. Use a pause for temporary anomalies like one-off spikes or weekend sales, resuming once traffic stabilizes. However, for permanent changes, such as a pricing update, new ad channel, or rebrand, the original data may no longer reflect your current audience. In these cases, restart the test to establish a new baseline.
4. Validate within-segment performance. A flat aggregate doesn't always mean a dead test. If your primary segment maintains its initial lift despite the total numbers leveling off, the variant is still performing; the sample just changed. Note the shift in composition, report the segment-specific results, and proceed with the rollout plan.
What a program that respects intent looks like
Instead of viewing "site visitors" as a monolith, effective programs draft hypotheses for specific audiences. They treat traffic composition as a primary metric in every test report rather than a secondary detail. By prioritizing segment-level results over aggregate data, these programs ensure that decisions to pause, conclude, or extend an experiment are based on shifts in the traffic mix rather than just fluctuations in top-line numbers.
Adopting this methodology helps teams avoid prematurely ending winning tests or implementing false winners across the site. Furthermore, it generates durable insights linked to specific audience profiles, ensuring that future acquisition efforts or seasonal shifts do not undermine previous findings.
FAQ
Do I need to segment every test?
No. Segment the tests where your hypothesis is audience-specific, or where traffic composition is likely to shift during the run. The rest can read on aggregate.
My sample size is already tight, won't segmenting shrink it further?
Yes, which is the argument for declaring the primary segment upfront and powering the test for that segment rather than for the whole site. A smaller, cleaner test beats a larger, contaminated one.
How big does a traffic shift need to be before it changes how I read the test?
Ten to fifteen percent movement in mix composition is the point to pause and check within-segment performance. Smaller shifts tend to absorb into normal variance.
Can I salvage a test where the mix changed mid-run?
Sometimes. If your primary segment held its pattern throughout, report on that segment and note the composition shift. If the segment itself was disrupted, restart
Subscribe to the Shoplift newsletter
Get insights like these emailed to you bi-weekly!
{{hubspot-form}}
